Role: Gen AI Platform Engineer · SAP CPIT (Corporate Process & IT)
Platform: SAP AI Launchpad — enterprise AI consumption and orchestration layer
Frontend: SAPUI5 · SAP Fiori
Backend: Node.js · Express.js
Integrations: AWS Bedrock · Google Vertex AI · Azure OpenAI
Auth: IAM / SigV4 · ADC service accounts · API key / Azure Entra ID
Overview
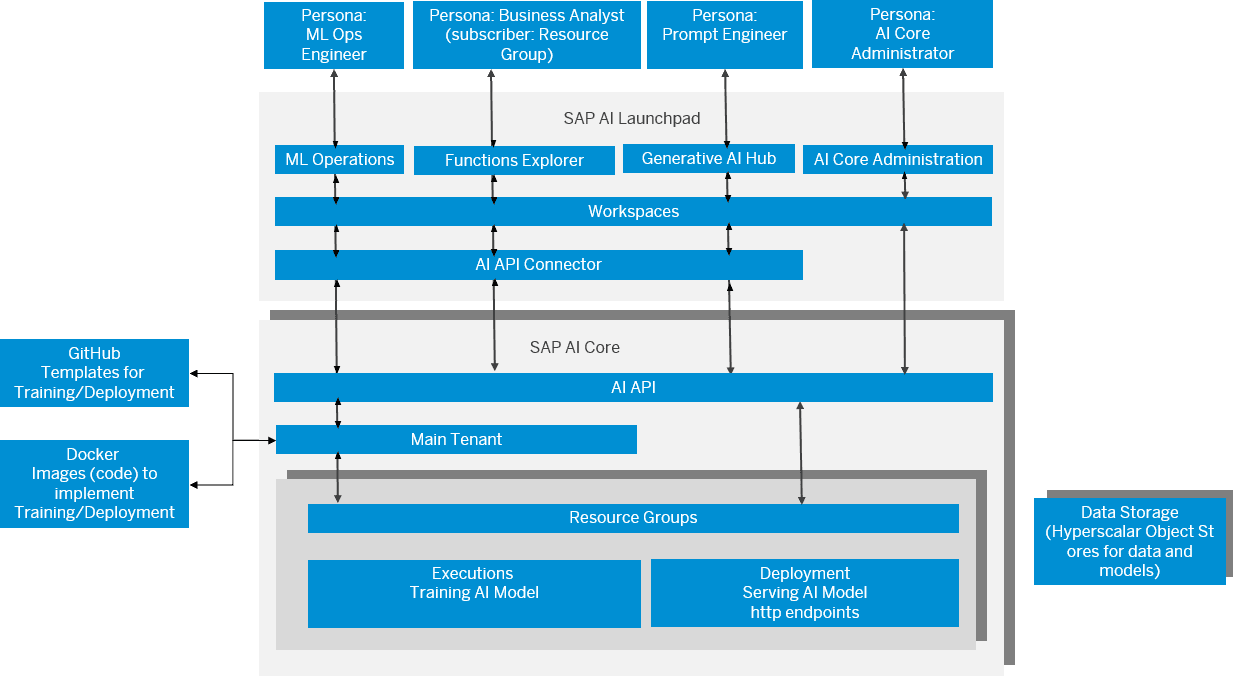
SAP AI Launchpad is an enterprise platform that gives SAP teams unified access to generative AI, without managing cloud credentials, provider SDKs, or model deployments themselves. It sits on top of SAP AI Core, which handles model execution and resource isolation, while the Launchpad provides the UI and API contract that product teams actually interact with.
My contributions spanned three areas: the multi-cloud LLM integration layer connecting the platform to AWS, Google Cloud, and Azure; Resource Group provisioning and LLM deployment within SAP AI Core; and the Orchestration feature — a no-code workflow builder inside the Generative AI Hub for composing multi-step AI pipelines.
Resource Group Provisioning & LLM Deployments
Every model available in the Launchpad first needs to exist as a deployment within an AI Core Resource Group — an isolated execution scope per tenant. I owned this lifecycle: creating Resource Groups, configuring model deployments, polling deployment status, and surfacing the resulting HTTP endpoints to the integration layer.
The backend work involved Express.js route handlers interacting with the AI Core AI API across the full deployment lifecycle (create → polling → ready). On the frontend, I built the corresponding SAPUI5 views, deployment status panels, resource group selectors, and configuration forms, following SAP Fiori design patterns.
Multi-cloud LLM Integration
The integration layer translates the platform's internal request format to each provider's API contract, handles authentication, and streams token responses back to the frontend as server-sent events (SSE).
AWS Bedrock — Claude
Uses @aws-sdk/client-bedrock-runtime with InvokeModelWithResponseStreamCommand. Auth via the AWS credential chain — IAM role in production, key/secret for local development. Claude's message schema is serialized into Anthropic's format before being wrapped in Bedrock's invocation envelope, then piped as an SSE stream to the HTTP response.
Google Vertex AI — Gemini
Uses @google-cloud/aiplatform with ADC service account auth. Chat format is mapped to Vertex's Content/Part schema, with generateContentStream driving token delivery. Gemini's HarmCategory/HarmBlockThreshold safety settings are surfaced through a dedicated SAPUI5 settings panel in the Launchpad UI.
Azure OpenAI — OpenAI, Meta Llama, Mistral
Uses the openai npm package in Azure mode, the same client, with azure_endpoint api_version, routes to GPT-4o, Llama 2/3, and Mistral Large deployments. Auth supports API key for development and DefaultAzureCredential from @azure/identity for production via managed identity.
Cross-cutting
All three integrations share the same Express route signature and SSE output format. Provider-specific errors, auth failure, rate limiting, context exceeded, and content policy violations are caught and normalized into a shared error taxonomy, keeping the SAPUI5 frontend provider-agnostic.
Orchestration Feature
The Orchestration service lets users compose and run multi-step AI pipelines from within the Generative AI Hub — no code required. Each pipeline is a sequence of configurable modules where the output of one feeds into the next:
Templating — compose reusable prompts with placeholders populated at inference time
Content Filtering — restrict the type of content passed to and returned from AI models at the pipeline level
Data Masking — anonymize or pseudonymize sensitive data before it reaches the model; with pseudonymization, masked values in the response are automatically restored
Grounding — enrich model context with external, domain-specific, or real-time data, enabling RAG-style pipelines without custom code
Translation — add input and output language translation as pipeline stages for end-to-end multilingual workflows
On the frontend, I built the workflow canvas in SAPUI5: a visual stage composer, per-module configuration panels, a live test console, and a JSON export view for teams consuming the configuration programmatically.
On the backend, the Express layer serializes the pipeline configuration into the orchestration schema expected by AI Core's orchestration deployment endpoint, injects OAuth tokens via client credentials flow, and streams the final LLM response over the same SSE interface used across the platform.
What I Learned
Provider abstraction is harder than it looks. AWS Bedrock, Vertex AI, and Azure all differ where it counts: request envelope format, streaming chunk structure, error verbosity, token counting, and auth token TTLs. Building a uniform interface forces a close reading of all three simultaneously — you end up with a sharper mental map of where cloud AI has genuinely converged versus where each provider is still doing its own thing.
Streaming is a first-class architectural concern. Getting SSE working across three providers, backpressure in Node.js, long-completion timeouts, chunk boundary edge cases, mid-stream error injection surfaced more complexity than expected. It deserves the same design attention as any other API contract, not a bolted-on afterthought.
Visual builders carry a hidden complexity budget. The Orchestration canvas looked like a UI feature in scope, but the engineering behind it- serializing graph state to a valid pipeline schema, validating module connections, keeping frontend state in sync with backend execution- was closer to a mini DSL runtime. Budget visual/interactive features generously.
Infra lifecycle should be code from day one. Early Resource Group and deployment provisioning was largely manual. As model and tenant counts grew, that overhead compounded fast. Any operation you'll repeat more than once should be scripted and version-controlled from the start.
Model versioning is an ops problem nobody plans for. Provider-side version changes mid-development cascaded into broken deployments and stale UI selectors because model IDs were embedded as static strings. A logical model registry, mapping stable names to current provider IDs, would have isolated those changes to a single record update.
What I Would Build Differently
TypeScript throughout. Three provider SDKs with distinct type shapes, in plain JavaScript, meant type errors surfacing at runtime that a type checker should have caught at the editor. The investment pays back quickly given how much provider-specific data flows through the Express layer.
Observability from day one. Without structured metrics per provider- latency, time-to-first-token, error rates, it was hard to detect silent degradation or make data-informed routing decisions. A metrics middleware should have been wired in from the start, not retrofitted later.
Circuit breakers per provider. When one provider had elevated error rates, there was no automatic fallback. Provider-level circuit breakers with graceful failover to an equivalent model on another cloud would have meaningfully improved resilience without any user-facing changes.
A cleaner orchestration state model. The canvas held pipeline config as UI component state and serialized it at submit time. A cleaner design would maintain a single source-of-truth config object and treat the canvas as a pure renderer of that state, making the pipeline independently testable and the UI easier to reason about.
Contract-level integration tests in CI. The reluctance to write streaming integration tests (slow, need real credentials) costs more time in manual verification than the tests would have taken. For SSE integrations, mocks aren't enough; only tests against real provider endpoints reliably catch API contract drift.