
As part of SAP’s AI Innovation Camp, I facilitated an Agentic AI Bootcamp for internal SAP engineering teams, focused on one goal:
Teaching developers how to build, test, and deploy enterprise-grade AI agents—not just prototypes.
The bootcamp followed a hands-on, learn-by-doing format, where participants moved from concept to a fully deployed, observable AI agent within a few days. [Bootcamps 2026_Goa | PowerPoint]
My Role
Designed and facilitated the end-to-end technical curriculum
Guided teams through real-world agent development workflows
Led hands-on coding sessions and live demos
Mentored participants through architecture, testing, and deployment challenges
Bootcamp Structure (Day 1 → Day 4)
Day 1 — Foundations & Agent Thinking
We established the core mental models behind agentic systems:
Introduction to Agentic AI and Software 3.0 paradigms
Understanding the difference between LLMs and autonomous agents
Deep dive into LangGraph as a stateful orchestration framework
Exploration of:
Agent architecture (planning, tools, memory)
Graph-based workflows (nodes, edges, state)
Hands-on:
Participants implemented their first LangGraph workflows and completed coding exercises in teams.
Day 2 — From Prototype to Engineering Discipline
Focus shifted from experimentation to production engineering practices:
Introduction to code-based agent architecture (North Star)
Setup using standardized internal framework (AIF Golden Path)
Applying Test-Driven Development (TDD) to agent workflows
Structuring repositories with:
Source, tests, deployment configs
Reusable templates and base classes
Hands-on:
Participants:
Migrated their notebook prototype into a production-ready repository
Wrote unit tests and validated agent behavior
Ran local execution and debugging workflows
Day 3 — Observability, Guardrails & Multi-Agent Use Cases
We introduced enterprise requirements for AI systems:
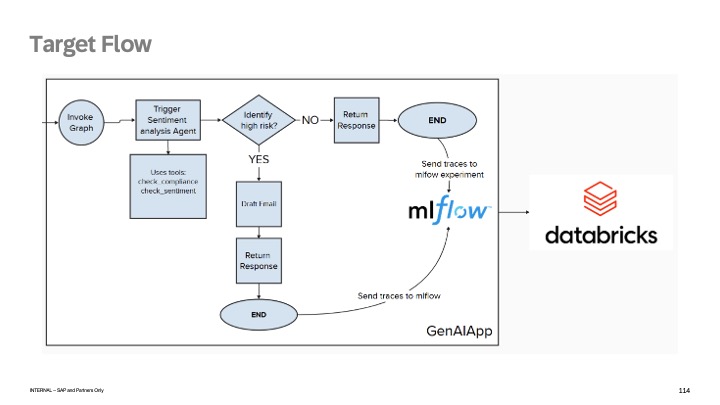
Building a real-world use case: Payment Risk Multi-Agent system
Designing agents with:
Sentiment analysis
Compliance checks
Risk evaluation
Implementing guardrails and evaluation frameworks using MLflow
Introducing:
Tracing and observability (full execution visibility)
LLM evaluation (LLM-as-a-judge, custom scorers)
Human-in-the-loop patterns
Hands-on:
Participants:
Extended their agent graph with real business logic
Integrated tracing pipelines
Evaluated outputs programmatically
Day 4 — CI/CD, Deployment & AgentOps
The final phase focused on shipping agents to production:
Full pipeline: build → test → deploy → operate
CI/CD with GitHub Actions (automated validation, deployment)
Deployment to Kyma (Kubernetes-based runtime on SAP BTP)
Introduction to AgentOps practices:
Monitoring
Evaluation
Logging and tracing
Hands-on:
Participants:
Added multi-step workflows (e.g., routing + email agent)
Deployed their agents to a live environment
Validated end-to-end execution through APIs
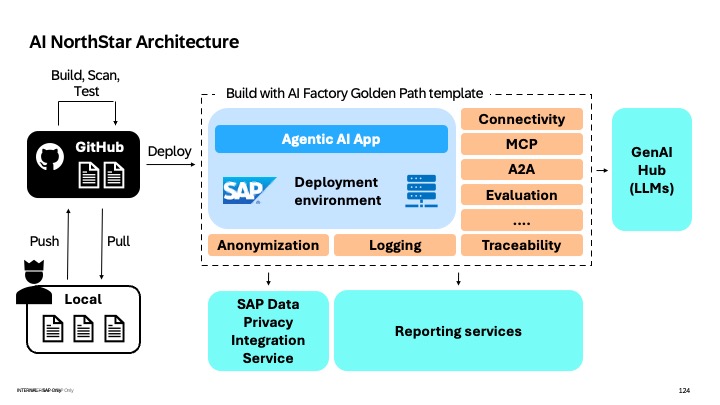
Architecture: Enterprise Agent Stack
The bootcamp was built around a production-grade architecture, including:
Agent Framework Layer
LangGraph for orchestration (stateful, multi-step workflows)
AI Platform Layer
Generative AI Hub for model access
Databricks for ML lifecycle and MLflow integration
Engineering Layer
AIF Golden Path templates for standardization
GitHub for version control and CI/CD
Observability Layer
MLflow tracing (full request lifecycle visibility)
Guardrails and evaluation pipelines
Deployment Layer
Kyma (SAP BTP Kubernetes runtime) for scalable deployment
This ensured developers could move from experimentation to production without reinventing infrastructure.
What Participants Built
By the end of the bootcamp, each team:
Built a multi-step agent workflow using LangGraph
Implemented tools and decision logic (e.g., sentiment + risk evaluation)
Added unit tests and TDD-based validation
Integrated:
MLflow tracing
Guardrails and evaluation
Deployed a working agent to a production-like environment (Kyma)
Outcome & Impact
Teams transitioned from Jupyter notebook prototypes → deployed, observable AI agents
Developers gained:
Full-stack understanding of agent systems
Production engineering practices (testing, CI/CD, deployment)
Experience working with real enterprise AI infrastructure
Established a repeatable model for:
Scaling agent development across teams
Reducing friction with standardized frameworks and tooling
Key Takeaways
AI agents require software engineering discipline, not just experimentation
Observability, testing, and CI/CD are as critical as model performance
Standardized frameworks (Golden Path) are essential for scaling AI adoption
The biggest unlock: enabling developers to focus on use cases instead of infrastructure